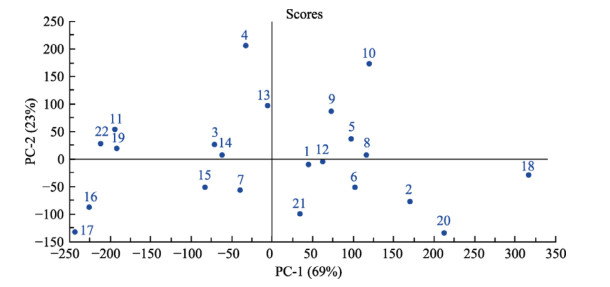
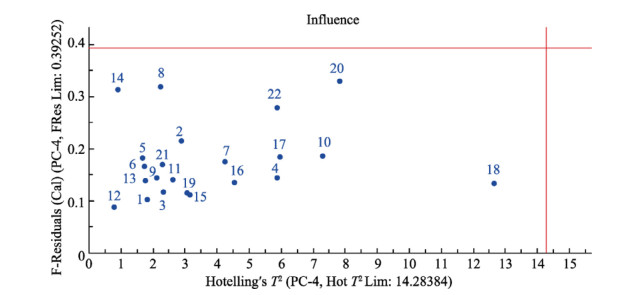
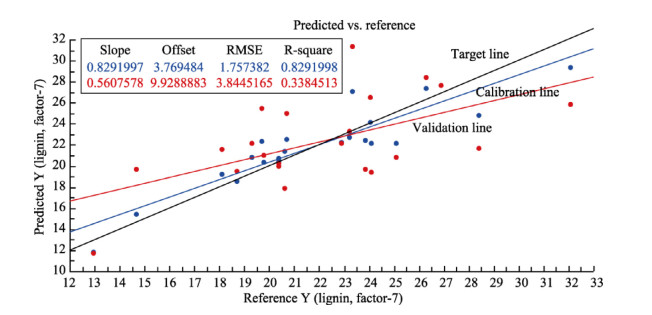
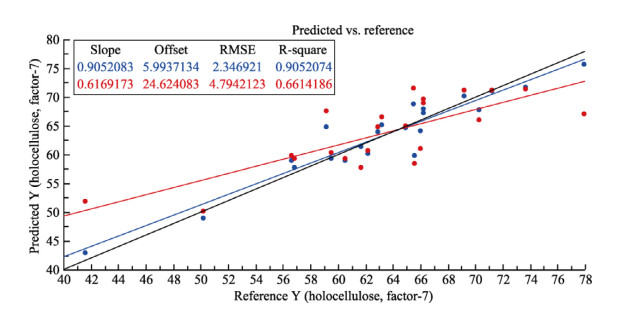
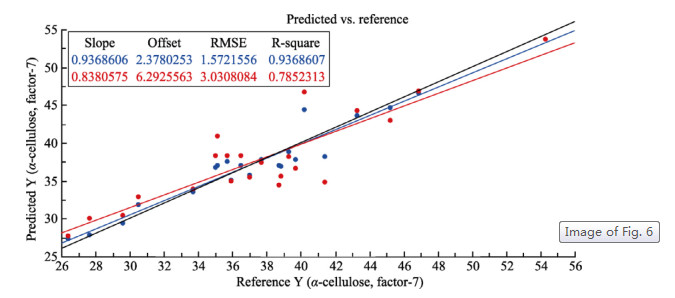
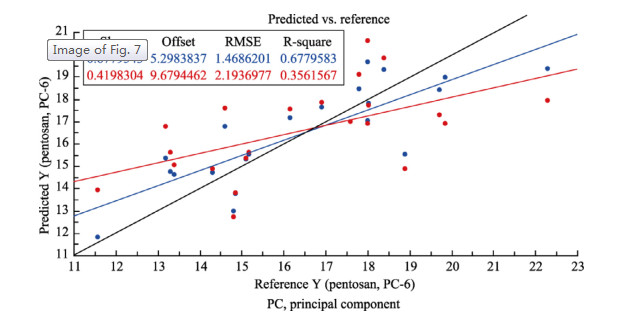
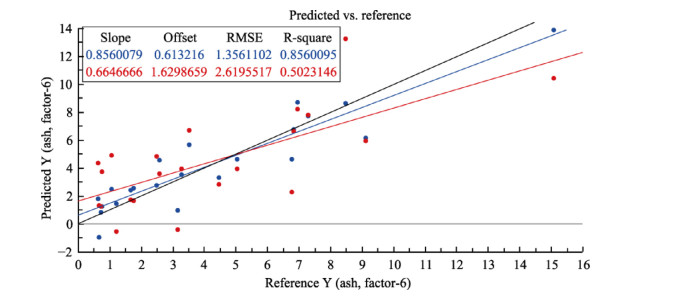
| Citation: | Mohammad Nashir Uddin, Taslima Ferdous, Zahidul Islam, M. SarwarJahan, M.A. Quaiyyum. Development of chemometric model for characterization of non-wood by FT-NIR data[J]. Journal of Bioresources and Bioproducts, 2020, 5(3): 196-203. doi: 10.1016/j.jobab.2020.07.005

|
|
Akhtaruzzamen, A.F.M., Shafi, M., 1993. Pulping of jute. Tappi J. 78, 106.
|
|
Alves, A., Santos, A., da Silva Perez, D., Rodrigues, J., Pereira, H., Simões, R., Schwanninger, M., 2007. NIR PLSR model selection for Kappa number prediction of maritime pine Kraft pulps. Wood Sci. Technol. 41, 491-499. doi: 10.1007/s00226-007-0130-0
|
|
Colares, C.J., Pastore, T., Coradin, V.T., 2015. Exploratory analysis of the distribution of lignin and cellulose in woods by Raman imaging and chemometrics. J. Braz. Chem. Soc. 26, 1297-1305. http://www.scielo.br/scielo.php?script=sci_arttext&pid=S0103-50532015000601297
|
|
Fahey, L.M., Nieuwoudt, M.K., Harris, P.J., 2019. Predicting the cell-wall compositions of solid Pinusradiata (radiata pine) wood using NIR and ATR FTIR spectroscopies. Cellulose 26, 7695-7716. doi: 10.1007/s10570-019-02659-8
|
|
Ferdous, T., Quaiyyum, M.A., Bashar, S., Jahan, M.S., 2020. Anatomical, morphological and chemical characteristics of kaun straw (Seetaria-ltalika). Nord. Pulp Pap. Res. J. DOI: 10.1515/npprj-2019-0057.
|
|
Fiserova, M., Gigac, J., Russ, A., Maholanyiova, M., 2012. Using NIR analysis for determination of hardwood kraft pulp properties. Wood Research, 57, 121-130. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=60ee8f4e88f59f4e4390dc0f5f983791
|
|
Hattori, T., Murakami, S., Mai, M.K., Yamada, T., Hirochika, H., Ike, M., Tokuyasu, K., Suzuki, S., Sakamoto, M., Umezawa, T., 2012. Rapid analysis of transgenic rice straw using near-infrared spectroscopy. Plant Biotechnol. 29, 359-366. doi: 10.5511/plantbiotechnology.12.0501a
|
|
He, L., Xin, L.P., Chai, X.S., Li, J., 2015. A novel method for rapid determination of alpha-cellulose content in dissolving pulps by visible spectroscopy. Cellulose 22, 2149-2156. doi: 10.1007/s10570-015-0652-9
|
|
Huang, C., Han, L., Liu, X., Ma, L., 2010. The rapid estimation of cellulose, hemicellulose, and lignin contents in rice straw by near infrared spectroscopy. Energy Sources Part A:Recover. Util. Environ. Eff. 33, 114-120. doi: 10.1080/15567030902937127
|
|
Hussain, M.A., Huq, M.E., Rahman, S.M., Ahmed, Z., 2002. Estimation of lignin in jute by titration method. Pak. J. Biol. Sci. 5, 521-522. doi: 10.3923/pjbs.2002.521.522
|
|
Jahan, M.S., 2009. Studies on the effect of prehydrolysis and amine in cooking liquor on producing dissolving pulp from jute (Corchoruscapsularis). Wood Sci. Technol. 43, 213-224. doi: 10.1007/s00226-008-0213-6
|
|
Jahan, M.S., Chowdhury, D.A.N., Islam, M.K., 2005. Alkalinesulphite anthraquinone methanol (ASAM) pulpig of jute. IPPTA J. 17, 37-43.
|
|
Jahan, M.S., Uddin, M.N., Akhtaruzzaman, A.F.M., 2016. An approach for the use of agricultural by-products through a biorefinery in Bangladesh. For. Chron. 92, 447-452. doi: 10.5558/tfc2016-080
|
|
Kothiyal, V., Jaideep, Bhandari, S., Ginwal, H.S., Gupta, S., 2015. Multi-species NIR calibration for estimating holocellulose in plantation timber. Wood Sci. Technol. 49, 769-793. doi: 10.1007/s00226-015-0720-1
|
|
Li, X.L., Sun, C.J., Zhou, B.X., He, Y., 2015. Determination of hemicellulose, cellulose and lignin in moso bamboo by near infrared spectroscopy. Sci. Rep. 5, 17210. doi: 10.1038/srep17210
|
|
Nuruddin, M., Chowdhury, A., Haque, S., Quaiyyum, M.A., 2011.Extraction and characterization of cellulose microfibrils from agricultural wastes in an integrated biorefinery initiative. Cellulose Chemistry and Technology. 45, 347-354. http://www.researchgate.net/publication/224001790_Extraction_and_Characterization_of_Cellulose_Microfibrils_from_Agricultural_wastes_in_an_Integrated_Biorefinery_Initiative
|
|
Poke, F.S., Raymond, C.A., 2006. Predicting extractives, lignin, and cellulose contents using near infrared spectroscopy on solid wood in Eucalyptusglobulus. J. Wood Chem. Technol. 26, 187-199. doi: 10.1080/02773810600732708
|
|
Rajesh, K., Ray, A.K., 2006. Artificial neural network for solving paper industry problems:a review. Journal of Scientific & Industrial Research. 65, 565-573. http://www.researchgate.net/publication/287438063_Artificial_neural_network_for_solving_paper_industry_problems_A_review
|
|
Roy, T.K., Mohindru, V.K., Behera, N.C., 1998. Jute for specialty pulp. IPPTA J. 10, 81-86. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC026056905
|
|
Saijonkari-Pahkala, K., 2001. Non-wood plants as raw materials for pulp and paper. Agricultural and Food Science in Finland. 10, 1-97. http://www.researchgate.net/publication/34974740_Non-wood_plants_as_raw_material_for_pulp_and_paper_?ev=auth_pub
|
|
Santos, A.J.A., Anjos, O., Pereira, H., 2016. Prediction of blackwood Kraft pulps yields with wood NIR-PLSR models. Wood Sci. Technol. 50, 1307-1322. doi: 10.1007/s00226-016-0837-x
|
|
Silva, J.C., Nielsen, B.H., Rodrigues, J., Pereira, H., Wellendorf, H., 1999. Rapid determination of the lignin content in sitka spruce (Piceasitchensis (bong.) carr.) wood by Fourier transform infrared spectrometry. Holzforschung 53, 597-602. doi: 10.1515/HF.1999.099
|
|
Uddin, M.N., Ahmed, S., Ray, S., Islam, M.S., Quadery, A.H., 2019. Method for predicting lignocellulose components in jute by transformed FT-NIR spectroscopic data and chemometrics. Nordic Pulp & Paper Research Journal 34, 1-9. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=DGYTnpprj-2018-0018
|
|
Uddin, M.N., Ray, S.K., Islam, M.S., Nayeem, J., Jahan, M.S., 2017. Development of method for rapid prediction of chemical components of dhaincha using FT-NIR spectroscopy and chemometrics. J. Sci. Technol. For. Prod Process. 6, 22-28. http://www.researchgate.net/publication/321307520_DEVELOPMENT_OF_METHOD_FOR_RAPID_PREDICTION_OF_CHEMICAL_COMPONENTS_OF_DHAINCHA_USING_FT-NIR_SPECTROSCOPY_AND_CHEMOMETRICS
|
|
Yeh, T.F., Yamada, T., Capanema, E., Chang, H.M., Chiang, V., Kadla, J.F., 2005. Rapid screening of wood chemical component variations using transmittance near-infrared spectroscopy. J. Agric. Food Chem. 53, 3328-3332. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=9d5f3fbcb36a20aa17c6b1449ddee72b
|
Figures(8) / Tables(2)

Copyright © 2019 Editorial Office of Journal of Bioresources and Bioproducts
Supported by: Beijing Renhe Information Technology Co. Ltd support: info@rhhz.net



 DownLoad:
DownLoad: